RAG TLDR¶
In essence¶
Bullet points¶
We split PDF molecules and other data sources into atoms and store them in a database.
We further process these atoms using traditonal Natural Language Processing techniques as needed to enhance search and reporting.
We vectorise these chunks to enable AI Semantic Search.
We can use other LLMs to analyse tables and images and generate content and metadata.
We use AI Agents to convert workflows into Agentic Retrieval Augmented Generation for Q & A and report making.
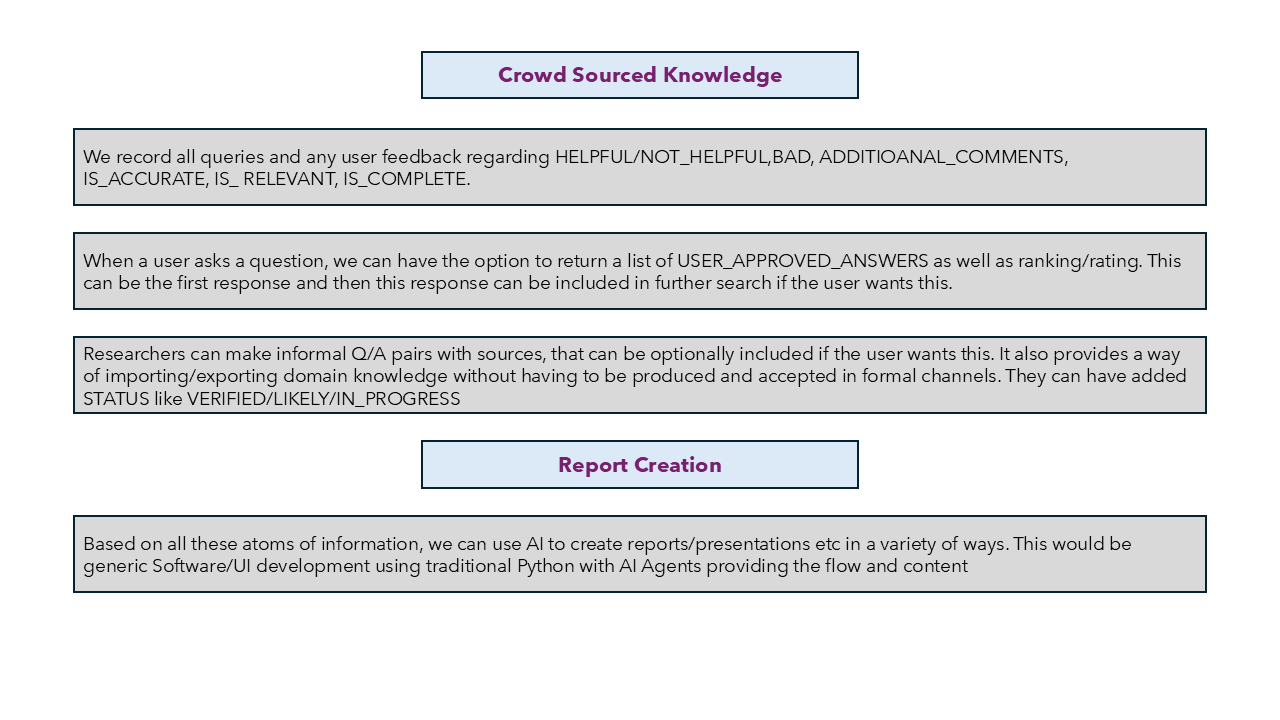
Users rate answers to provide a 'crowd sourced' information store - IS_ACCURATE, IS_RELEVANT, IS_COMPLETE and comments/notes added. We can use this information to provide fast answers or aggregate information from many sources along with the crowd source answers
Importing and exporting of Knowledge Bases and other data sources enables pooling of knowledge between organisations.
All componets are modular enabling customisation as needed as well as offering a range of options for users to choose from.
What would a human researcher do...?
A modular system¶
Details¶
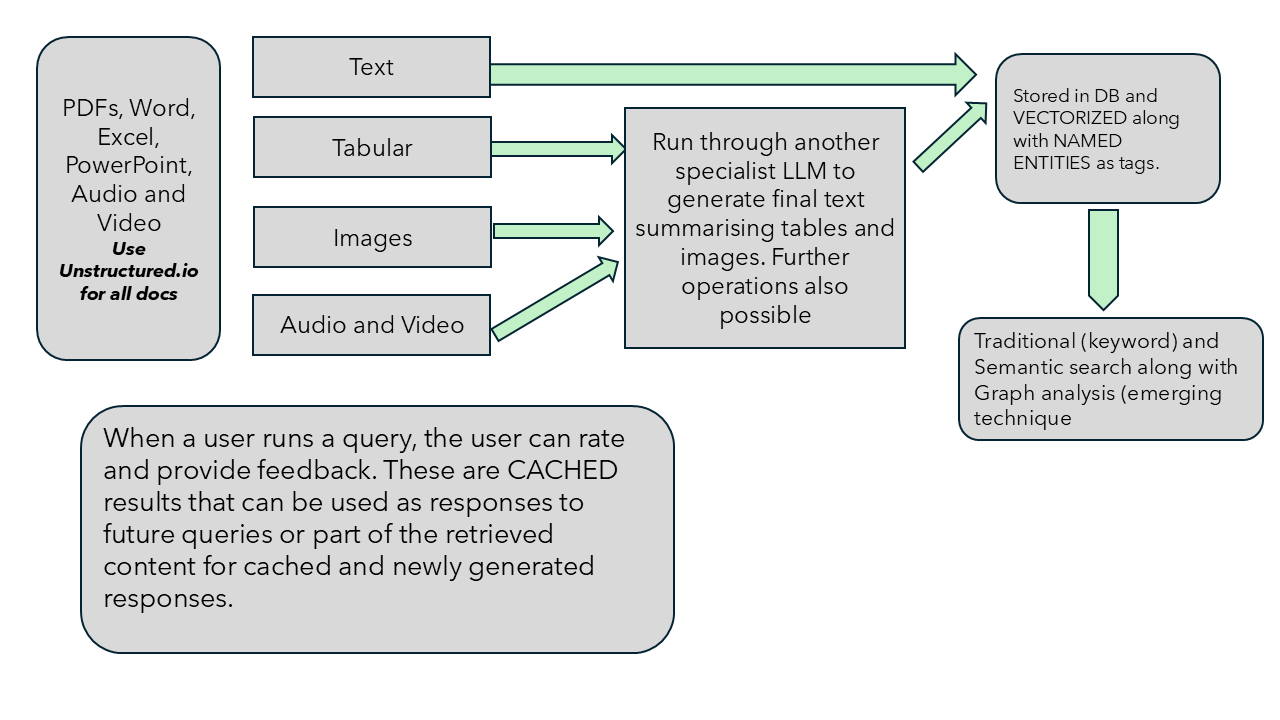
Processing data sources¶
If TEXT, we can use Natural Language Processing techniques to summarise, extract entities and rephrase content for better semantic search and also tradional Full Text Search in Postgressql database.
If TABLE data, we get both the text summary and HTML table structure. We can then use other LLMs to query the data.
If IMAGE, we store the image and summary and then use other LLMs to anyalyse the image.
(Audio and Video can be processed to.)
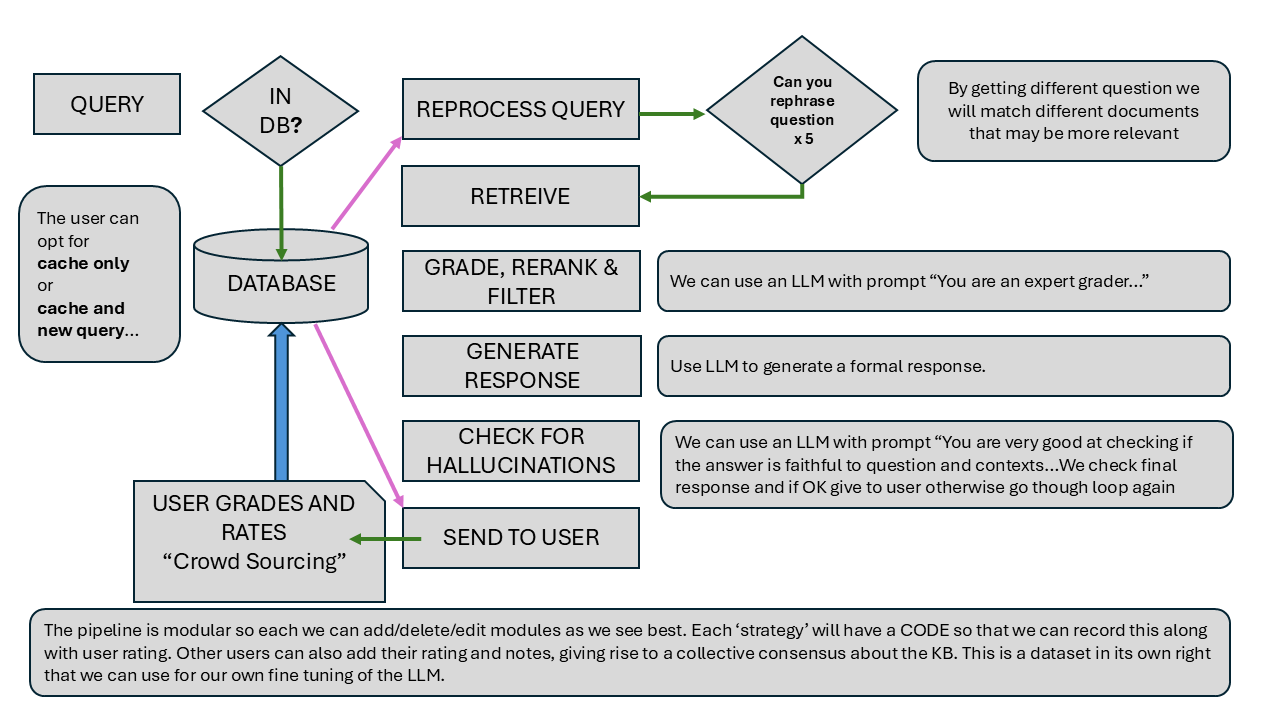
Process information¶
We can use Natural Language Processing techniques to summarise, extract entities and rephrase content for better semantic search and also tradional Full Text Search in Postgressql database.
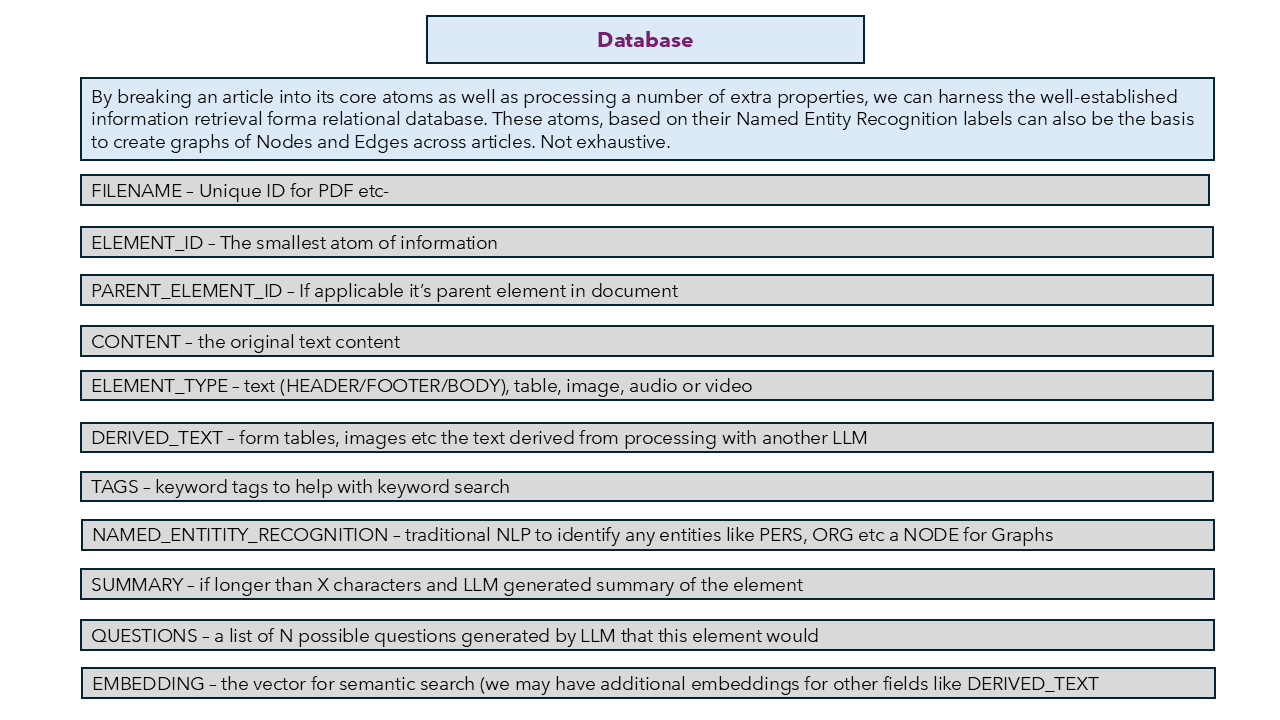
We can also use Graph Databases to develop retlationships between atoms and molecules for further retrieval capabilites once we know what relationships we are interested in.
This provides an OpenVerdict type service for Question/Answers with sources.
Agentic RAG strategies¶
There are many and growing number of strategies for doing semantic search.
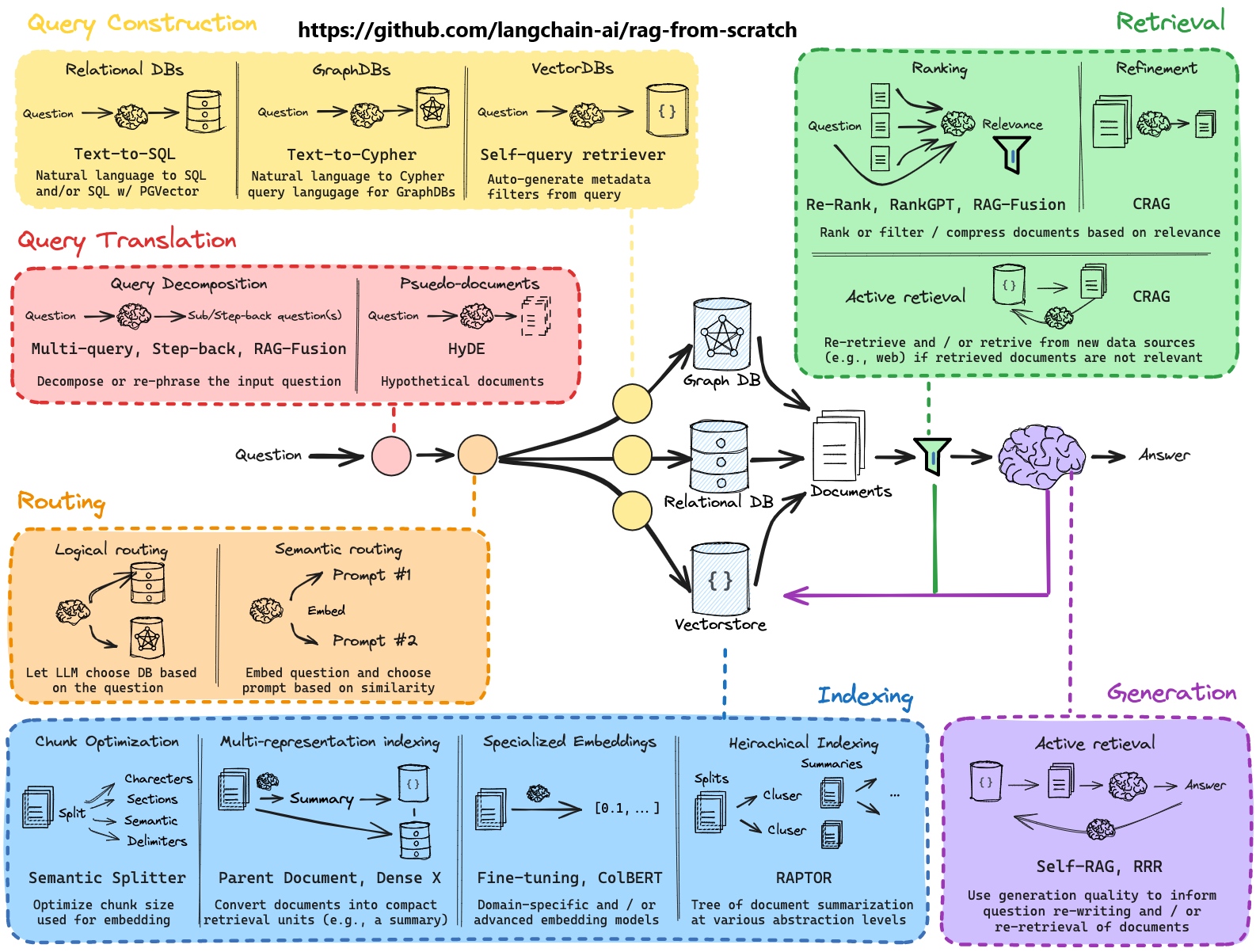
We can use AI Agents to be researchers creating report etc using the knowledge base or other external knowledge sources.
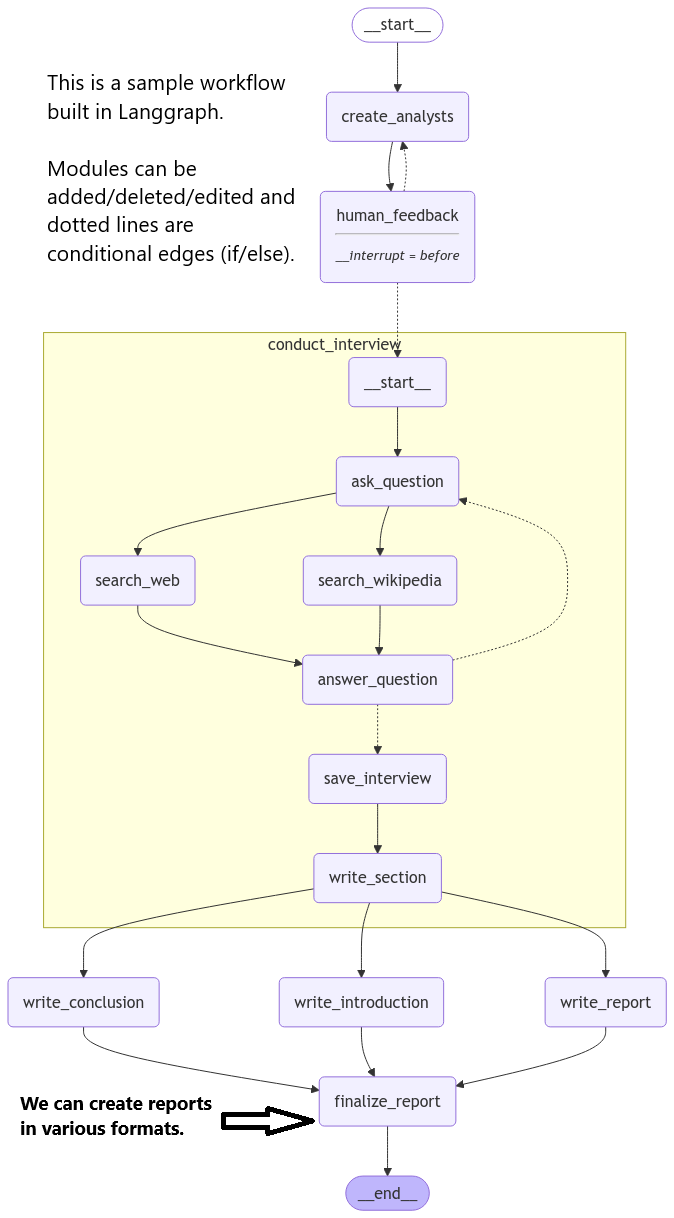
A protocol for Knowledge Base import/export with other knowledge sources enables pooling of knowledge. It also enable researchers 'notes' to be use, annoted with current verification status.
Reports would list and summarise knowledge from:
- Crowd sourced answers
- Documents in the knowledge base
- External knowledge sources
- Custom workflows can be made using frameworks like Langgraph etc.
Being a modular system, the system can be adapted as needed as well as offering a range of options for users to choose from.
User rated answers¶
We also enable users to rate the responses creating a 'crowd sourced information store' that can either provide fast answers or aggregate information from many sources along with the crowd source answers.